

"Maximizing Efficiency: The Integration of Consistent Hashing and Load Balancing"

Android App Developer & Product Engineer @Mosaic Wellness. 4x Hackathon Winner. SWE Intern @Bonito Designs, @Legato Health Tech. Open for Freelance gigs. Documenting my tech journey via Hashnode & ranting about my life on Twitter.
Introduction
Welcome back to the system design series. In this article, we will be covering the concept of Load Balancers & Consistent Hashing. In the previous article, we covered the difference between Horizontal & Vertical scaling.
In this blog post, we'll take a closer look at load balancers with consistent hashing and explore how they can be used to achieve high availability and scalability for web applications and services.
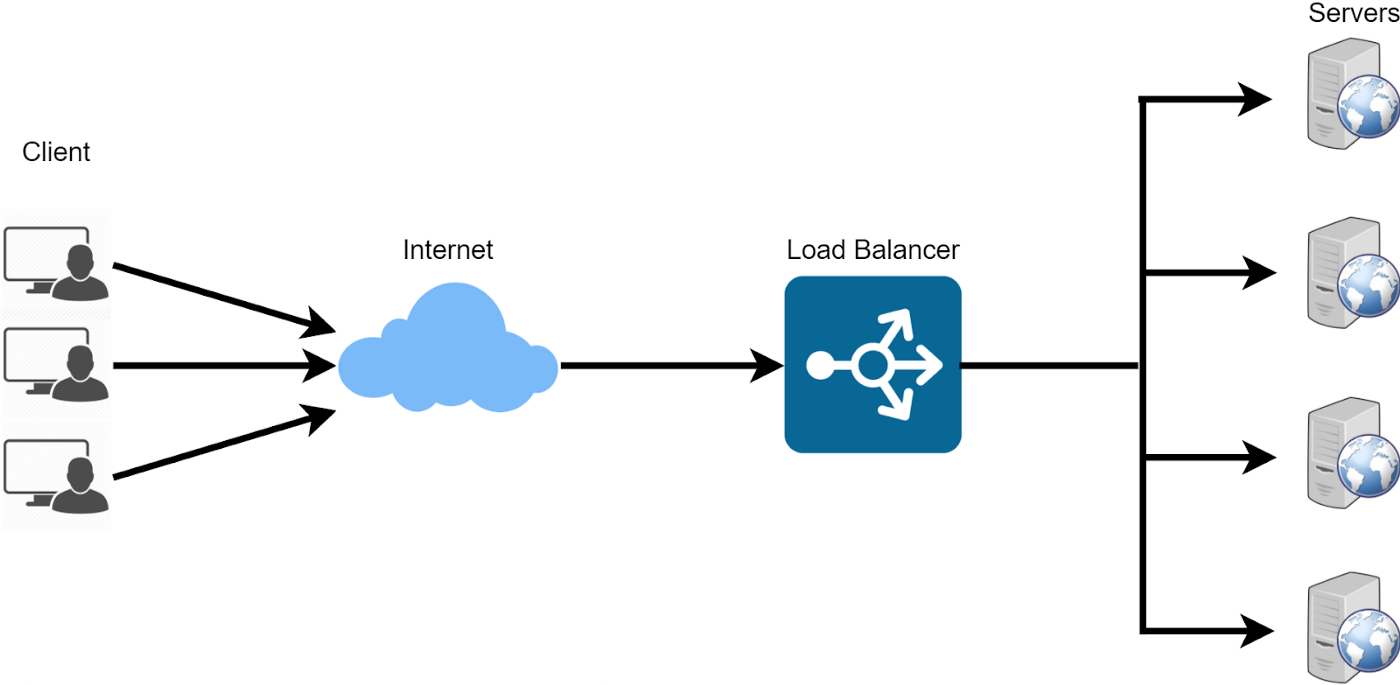
What is a Load Balancer?
Remember horizontal scaling? A load balancer is a crucial component of any modern distributed system that helps to distribute network traffic across multiple servers to prevent any one server from becoming overwhelmed. By distributing the load across multiple servers, a load balancer can help to optimize the performance, availability, and scalability of web applications and services.
What is Consistent Hashing?
Load balancing can be achieved through a variety of algorithms, including round-robin, least connections, IP hash, and consistent hashing. Consistent hashing is a popular algorithm that has become increasingly popular in recent years due to its ability to minimize the disruption caused by adding or removing servers from the cluster.
How does Load Balancer work?
Load balancers work by distributing incoming network traffic across multiple servers to prevent any one server from becoming overwhelmed.
For example, let's say you are running a web application that receives a large amount of traffic. The load balancer will examine each incoming request and use a pre-defined algorithm to decide which server to route the request to. The algorithm can be a round-robin, a simple hash, or consistent hashing.
How does consistent hashing work?
Consistent hashing is a technique where servers and requests are hashed using a hash function and placed on a ring-like structure. The requests are sent to the immediate next server, which is present in the clockwise direction.

In the above image, Harry, George, Alice, etc are requests and A1, B1 etc are the servers.
Advantages of Consistent Hashing
Scalability: Consistent hashing is highly scalable because it allows for the addition or removal of servers without requiring a complete remapping of data. This makes it easier to scale up or down the size of a distributed system.
Fault-tolerance: Because data is distributed across multiple servers, consistent hashing is resilient to failures of individual servers. When a server fails, its data can be redistributed to other servers in a way that minimizes disruption.
Load balancing: Consistent hashing ensures that data is evenly distributed across servers, which helps to balance the load on each server. This can help to prevent the overloading of individual servers and improve the overall performance of the system.
Major Problem
One major disadvantage of consistent hashing is an uneven distribution of keys when the number of servers is less. If we remove server A1 from the above image, all the requests will land on B1 and it will increase the load on it.
Solution
To solve this, we can use the concept of virtual servers. In this technique, every server is hashed with k different hash functions.
This means each server has k unique spots on the ring. So if we have 3 servers and k=3, we have 9 different server points on the hash ring(6 are virtual). Now, even if we remove one server, we will have 6 server points on the ring and a single server won’t take a lot of loads.
The ideal value of k when implementing the "virtual nodes" technique in consistent hashing depends on several factors, including the size of the cluster, the number of physical nodes, and the desired level of key distribution.
Code for Consistent Hashing
Consistent Hashing is just an algorithm so there must be code for the algorithm as well right? Well, YES! Here is the code for implementing the consistent hash with the 'virtual server' concept.
// Class to represent a node on the hash ring
class Node {
constructor(name, address) {
this.name = name;
this.address = address;
}
}
// Class to represent the hash ring
class HashRing {
constructor(hashFunction, replicas=100) {
this.hashFunction = hashFunction;
this.nodes = [];
this.replicas = replicas;
this.nodeMap = new Map();
}
// Add a node to the hash ring
addNode(node) {
this.nodes.push(node);
this.rebuildMap();
}
// Remove a node from the hash ring
removeNode(node) {
this.nodes = this.nodes.filter((n) => n.name !== node.name);
console.log(this.nodes, 111);
this.rebuildMap();
}
// Get the node responsible for a given key
getNodeForKey(key) {
const hash = this.hashFunction(key);
const nodeIterator = this.nodeMap.values();
let next = nodeIterator.next();
while (!next.done && next.value.hash <= hash) {
next = nodeIterator.next();
}
if (next.done) {
next = this.nodeMap.values().next();
}
return next.value.node;
}
// Rebuild the mapping of hash values to nodes
rebuildMap() {
this.nodeMap.clear();
for (const node of this.nodes) {
for (let replicaNo = 1; replicaNo <= this.replicas; replicaNo++) {
const hashString = node.address + replicaNo.toString();
const hash = this.hashFunction(hashString);
this.nodeMap.set(hash, { hash, node });
}
}
}
}
// Simple hash function using the built-in hash function
function hashFunction(str) {
let hash = 0;
for (let i = 0; i < str.length; i++) {
hash = (hash << 5) - hash + str.charCodeAt(i);
hash |= 0;
}
return hash;
}
// Create a hash ring with our hash function and providing value of k.
const hashRing = new HashRing(hashFunction, 20);
// Add some nodes to the hash ring
hashRing.addNode(new Node("Node 1", "10.0.0.1"));
hashRing.addNode(new Node("Node 2", "10.0.0.2"));
hashRing.addNode(new Node("Node 3", "10.0.0.3"));
// Get the node responsible for a key
const node = hashRing.getNodeForKey("my_key");
console.log(`Node responsible for my_key: ${node.name} at ${node.address}`);
// Remove a node from the hash ring
hashRing.removeNode(new Node("Node 1", "10.0.0.1"));
// Get the node responsible for the same key again
const node2 = hashRing.getNodeForKey("my_key");
console.log(
`Node responsible for my_key after removing Node 1: ${node2.name} at ${node2.address}`
);
Conclusion
So that was it for load balancers and consistent hashing. This article was just a starting point to explain the concept of load balancers and one possible way to implement it. I hope you learned something new today!



